For the Complier it was decided to use a hash table for the symbol table due to hash tables having fast lookup speeds. Hash tables are arrays paired with a hash function that uses symbol names to calculate the index of the array where the symbol is to be stored:
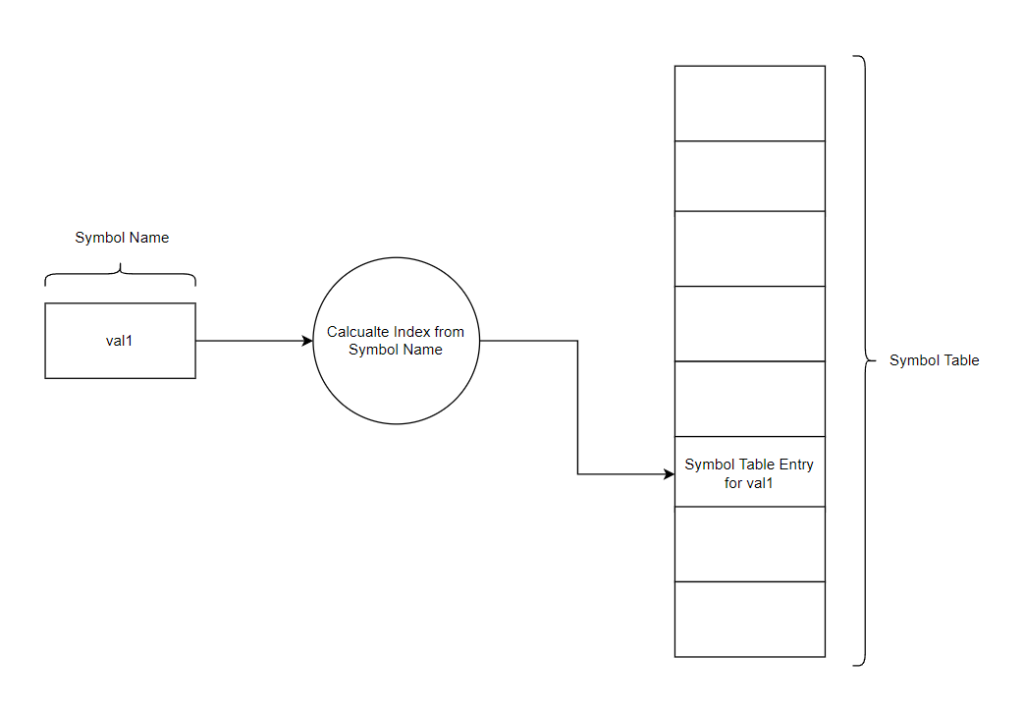
The hash function calculates the index to store the symbol by summing the decimal values of the ASCII characters in the symbol name, then taking the remainder of the sum divided by the size of the hash table’s array. See below for the function used to calculate the index of the hash table to store a symbol:
unsigned int hash(char* key) {
unsigned int hashval = 0;
// sum ASCII values of characters
while (*key) {
hashval += *key;
key++;
}
return hashval % COLUMN_SIZE; // return modulo on size of table
}It is possible to have what is called a collision where the same index is calculated for different symbol names. In this case a linked list is created at that index of the hash table. For example, say val1 and val2 ended up having the same index calculated from the hash function, the table would look like the figure below:
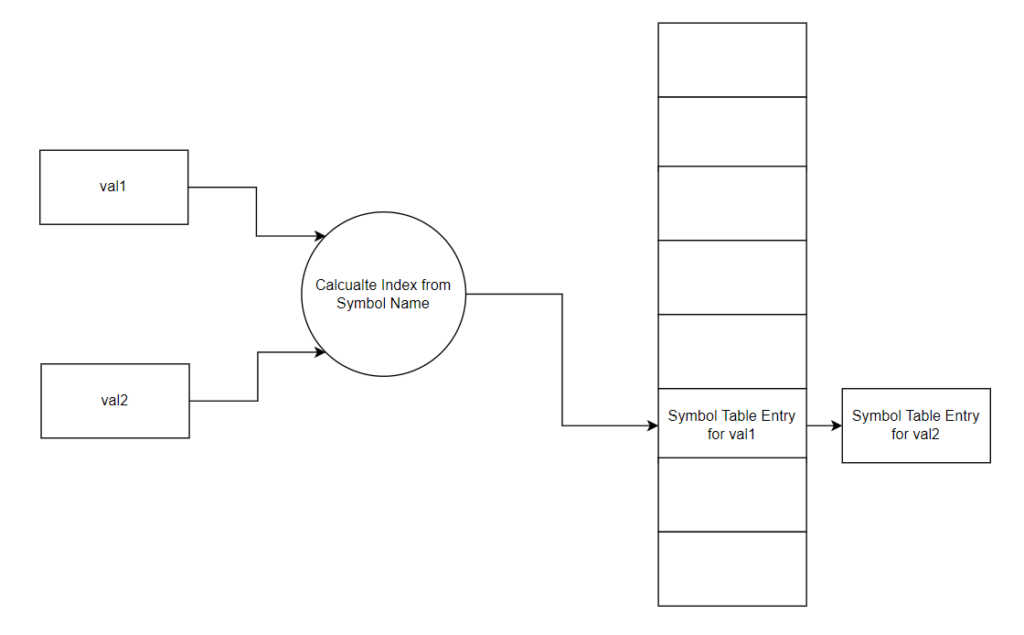
This allows for multiple values to be stored at a single index of the hash table. The downside of collisions is that they increase the lookup time as the Compiler must perform a linear search of each entry of the linked list to look for specific a symbol name.
Another important thing to consider is that a C program can have multiple symbols that share a name if they are in different scopes of the program. This will cause a collision issue as the same index will be calculated for each symbol; however, the names of the symbols will be the same so a search through a linked list cannot be used as done before . To overcome this, it was decided to give each scope of the program it’s own symbol table.
Each scope contains the next scope, the previous scope, sub scope, the scope number (global would be 0, number increases the further away it is from the global scope), and a symbol table:
// Addition to symtab.h
typedef struct scope
{
struct scope* next;
struct scope* prev;
struct scope* sub_scope;
int scope_num;
symbol_t** table;
}scope_t;Functions were created to initialize, increment, and decrement scopes:
// Addition to symtab.c
scope_t* init_scope() {
// allocate memory
scope_t* scp = (scope_t*)calloc(1, sizeof(scope_t));
scp->next = NULL;
scp->prev = NULL;
scp->sub_scope = NULL;
scp->scope_num = curr_scope;
scp->table = (symbol_t**)calloc(COLUMN_SIZE, sizeof(symbol_t*));
return scp;
}
void incr_scope() {
scope_t* scp = init_scope();
current_scope->next = scp;
scp->prev = current_scope;
current_scope = scp;
curr_scope++;
}
extern void decr_scope() {
current_scope = current_scope->prev;
curr_scope--;
}The main function was updated to create a global and main scope:
// Addition to main.c
int curr_scope = 0;
int curr_sub_scope = 0;
int ROW_SIZE = 10;
int COLUMN_SIZE = 20;
float RESIZE = 0.5;
scope_t* current_scope;
scope_t* global_scope;
scope_t* main_scope;
int main(int argc, char* argv[]) {
global_scope = init_scope();
current_scope = global_scope;
incr_scope();
...
The Parser was also updated to increment the scope whenever the grammar for a function is encountered (note, may need to add the incr_scope() function in other areas of the Parser as the grammar of the Compiler grows):
// Addition to Parser.y
functions:
functions function {
AST_Node_StateList* temp_funclist = (AST_Node_StateList*) $1;
$$ = new_ast_statelist_node($1, $2, temp_funclist->statement_cnt + 1);
}
| function {
incr_scope();
$$ = new_ast_statelist_node(NULL, $1, 1);
}
;