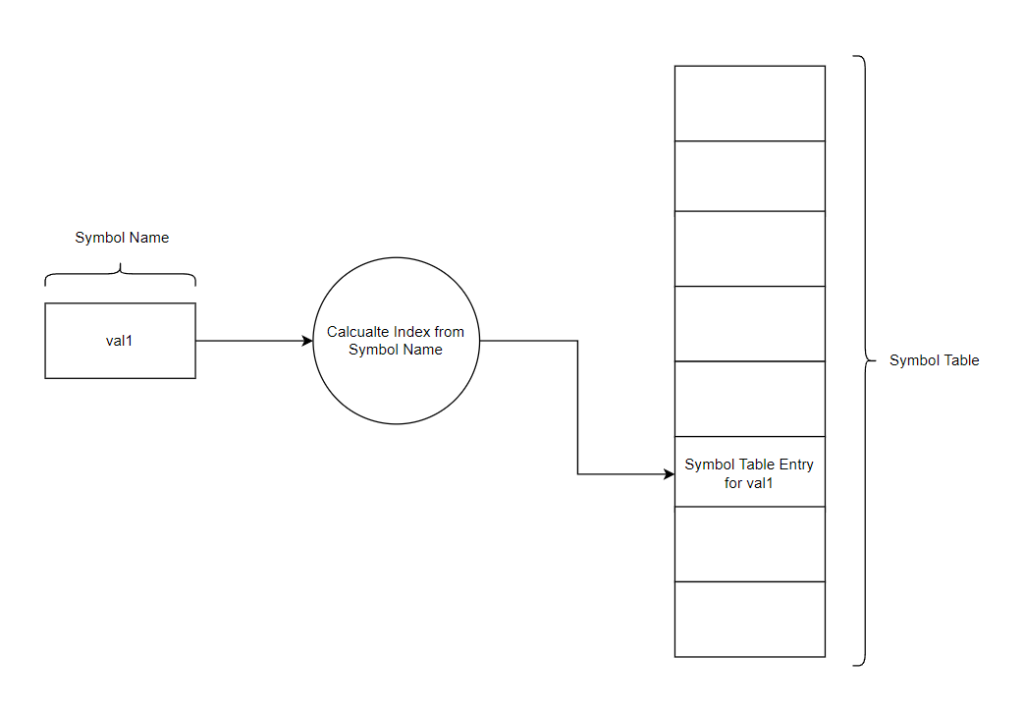
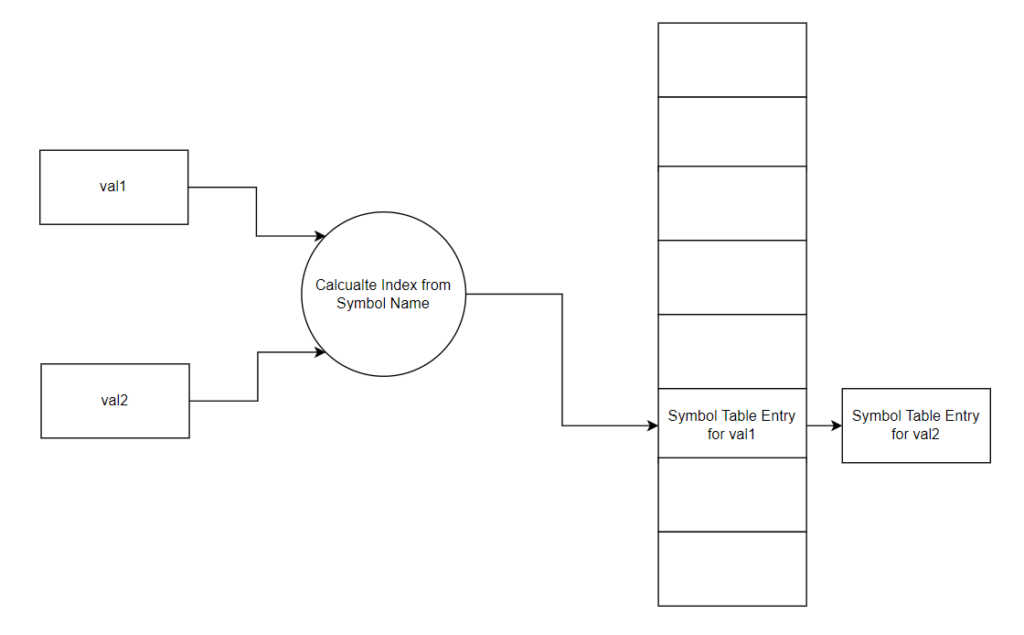
Details of variables and functions are stored in the Complier’s symbol table so that the Complier can later access information for the symbol. The Complier uses the information in the symbol table to help perform semantic analysis and generate assembly code.
The first field of the symbol table is a string for the symbol name. The symbol name is stored as it helps the Complier find the symbol in the symbol table:
#define MAXIDLEN 31 // max length of identifier (defined by C standard)
typedef struct symbol {
char id[MAXIDLEN];
}symbol_t;Sometimes the symbol table will create a collision, in this case a linked list at that index of the symbol table is required. Therefore, each symbol has a field to allow the creation of a linked list:
typedef struct symbol {
char id[MAXIDLEN];
struct symbol* next;
}symbol_t;For now the symbols can either be for a variable or a function (may have more types in the future). This means a field is needed to tell the Complier whether the symbol is for a variable or function:
typedef struct symbol {
char id[MAXIDLEN];
int sym_type;
struct symbol* next;
}symbol_t;For semantic analysis, it is also important to store what variable type the symbol is for:
// Enum used for the different C variable types
typedef enum Variable_t
{
CHARtype,
DOUBLEtype,
FLOATtype,
INTtype,
LONGtype,
SHORTtype,
VOIDtype,
STRtype,
NUMtotal //Stores how many variables types are handled
} VariableType;
typedef struct symbol {
char id[MAXIDLEN];
int sym_type;
VariableType data_type;
struct symbol* next;
}symbol_t;In the creation of the symbol table, it was decided that each scope of the C program should have its own scope. This means that the Complier must know the name and scope of a symbol to locate it:
// Updates to ast.h
/* Function Nodes */
typedef struct AST_Node_Func_t {
Node_Type type;
char* funcname;
scope_t* scope;
AST_Node* statement_list;
AST_Node* param_list;
} AST_Node_Func;
typedef struct AST_Node_Func_Call_t {
Node_Type type;
char* funcname;
AST_Node* param_list;
scope_t* scope;
} AST_Node_Func_Call;
typedef struct AST_Node_ID_t {
Node_Type type;
char* varname;
int vartype;
scope_t* scope;
Value val;
} AST_Node_ID;
// Update to symtab.h
typedef struct symbol {
char id[MAXIDLEN];
int scope;
int sym_type;
VariableType data_type;
struct symbol* next;
}symbol_t;Variables will have values stored in memory at a relative offset to the base pointer of a stack frame. To allow the complier to access variables stored in memory, a field for the base pointer offset was added (note this field is used for variables, it is not used for functions):
typedef struct symbol {
char id[MAXIDLEN];
int scope;
int sym_type;
VariableType data_type;
int bp_offset;
struct symbol* next;
}symbol_t;Functions won’t have values stored in memory like variables; however, it is useful to store how many parameters are passed to the function (i.e., allows the Complier to know how many variables must be popped from the stack in a return from a function call). Therefore, a field was added to store how many parameters a function has (this will have to be updated in the future to account for parameter types):
typedef struct symbol {
char id[MAXIDLEN];
int scope;
int sym_type;
VariableType data_type;
int bp_offset;
int param_count;
struct symbol* next;
}symbol_t;Finally, a field was added to store the values of variables:
typedef union Value {
int ival;
double dval;
long lval;
float fval;
char cval;
char* sval;
short shval;
} Value;
typedef struct symbol {
char id[MAXIDLEN];
int scope;
int sym_type;
VariableType data_type;
Value value;
int bp_offset;
int param_count;
struct symbol* next;
}symbol_t;