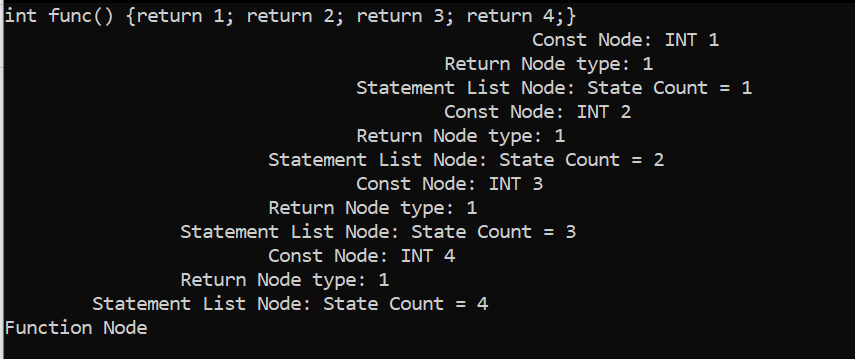
Taking a look at how the function and statement types were previously implemented in the Parser, it is observed that a function can only hold one statement node:
function:
INT ID OP_PAR CL_PAR OP_BRACE statement CL_BRACE {;}
;
statement:
return_st {;}
;In reality, a function will contain many statements, so the Parser must be modified. To allow a function to contain multiple statements, a statement list node will be used. The statement list node will contain a pointer to a statement node as well as a pointer to another statement list node:
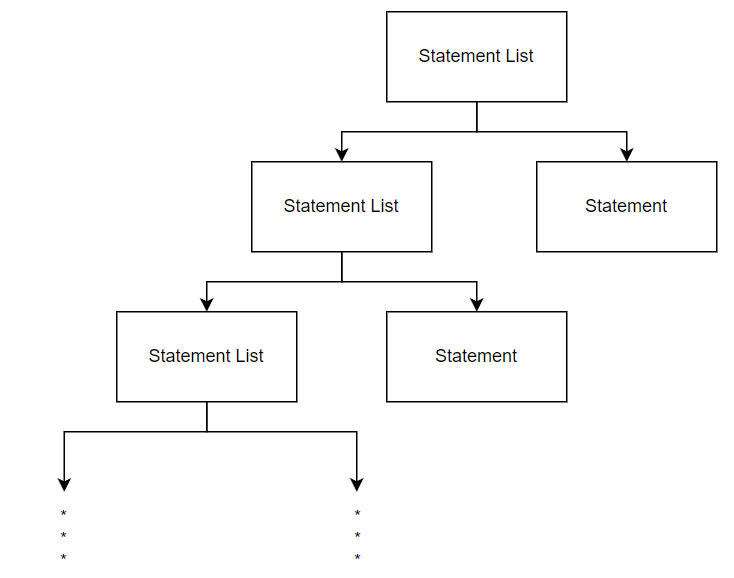
Since a statement list node contains a pointer to another statement list node, any amount of statements can be contained within a single statement list tree. Therefore, if the function node contains a statement list node rather than a statement node, any amount of statement nodes can be contained within a single function.
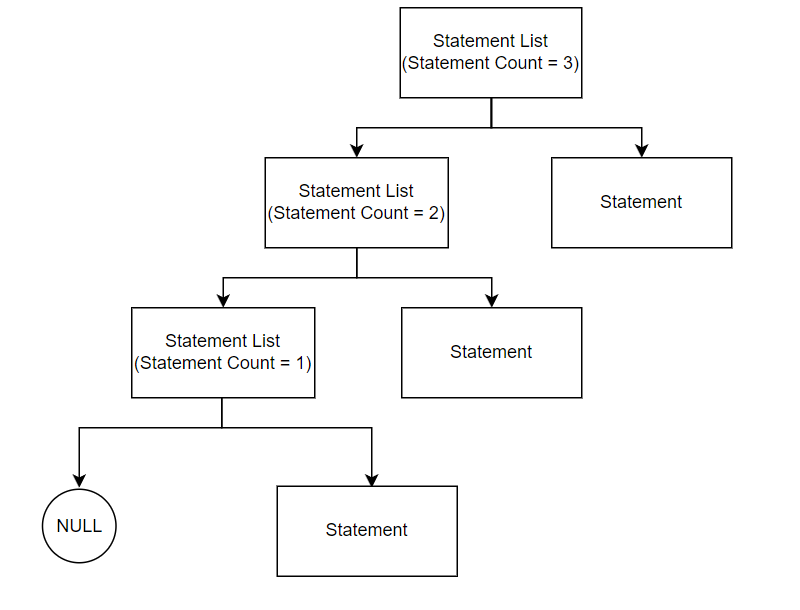
Another field to be implemented in the statement list node is the statement count. The statement count represents how many statement nodes can be found from traversing the tree starting at that particular statement list node. The statement count will be useful later when translating to the XM3 language as the CEX instruction (conditional execution) needs to know the amount of instructions to run/not run. Below shows a statement list tree that uses the statement count:
Now, to implement the statement list node into the compiler. First, a struct for a statement list node is needed for the abstract syntax tree. It will contain fields for the node type, a statement list node pointer, a statement node pointer, and an integer for the statement count:
typedef struct AST_Node_StateList_t {
Node_Type type;
AST_Node* statelist;
AST_Node* statement;
int statement_cnt;
} AST_Node_StateList;Then, the Parser needs recursive grammar to enable the creation of statement list nodes. This will require a new %type <node> called statements (refer to the post “Initial Parser” for an explanation of bison types). The two possible grammars for a statements type will be:
- A statements type followed by a statement type
- A single statement type.
This allows a statements type to represent any amount of subsequent statement types as “statements” is replaced with “statement” or “statements statement” where “statements” can continue to be replaced. See the below code for the implementation of the “statements” type grammar in the Parser (note: function now uses the statements type rather than the statement type):
function:
INT ID OP_PAR CL_PAR OP_BRACE statements CL_BRACE {
$$ = new_ast_func_node($6); }
;
statements:
statements statement {;}
| statement {;}
;The example below shows a visual representation of the creation of a statements type. Say 4 subsequent statement types are passed to the Parser (note statement1 is passed to the Parser first, and statement4 is passed to the Parser last):
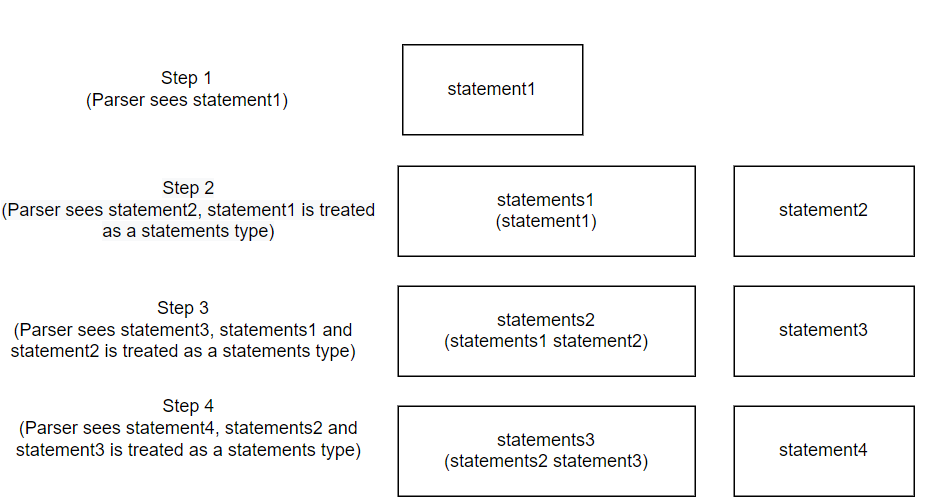
The Parser has been updated to have recursive grammar; however, it still needs C code to create the statement list nodes. For this, the below function is used to create statement list nodes:
AST_Node* new_ast_statelist_node(AST_Node* stmlist, AST_Node* stm, int stmcnt)
{
AST_Node_StateList* node = malloc(sizeof(AST_Node_StateList));
node->type = STATELIST_NODE;
node->statelist = stmlist;
node->statement = stm;
node->statement_cnt = stmcnt;
return (AST_Node*)node;
}Now, it is needed to update the C code in the actual Parser. Again, two cases must be considered as the grammar for the statements type can either be “statements statement” or just “statement”.
First, take the case where the statements type is just “statement”. In this case, only a single statement needs to be handled. Therefore, the pointer to the next statement list node should be NULL. Also, since there are no further statement list nodes, the statement count should be 1. Therefore, the Parser will call the function new_ast_statelist_node with the parameters of statement list node pointer = NULL, statement node pointer = $1 (pointer to statement node returned from statement type), and statement count = 1:
statements:
statements statement {;}
| statement { $$ = new_ast_statelist_node(NULL, $1, 1);}
;Then, the next case of the statements type being “statements statement”. Take the previous example of there being 4 subsequent statement types. Initially the Parser will only see the first statement. This will be handled as described above for the “statement” case. Then, when the Parser is passed the second statement it will see the grammar as:

In this case, statements1 is a statement list node where the statement node pointer is to the node for statement1 and statement2 is a statement node. Therefore, the statement list node created for statement2 should have the next statement list node pointer point to statements1, should have the statement node pointer point to statement2, and should have the statement count be 1 greater than that of the statement count in statements1. See below for a visual representation of the abstract syntax tree nodes being created :
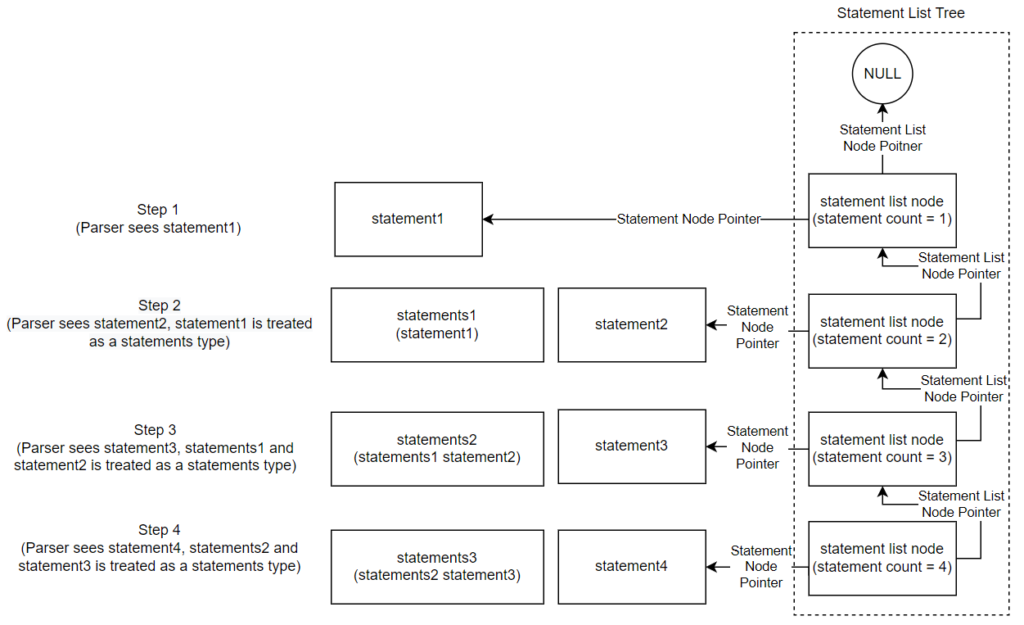
Implementing the case of “statements statement” in the Parser requires the statement count field node from statements node to be known. To do this, a temporary node is created to access the field. See below for the implementation of the “statements statement” case:
statements:
statements statement {
AST_Node_StateList* temp_statelist = (AST_Node_StateList*) $1;
$$ = new_ast_statelist_node($1, $2, temp_statelist->statement_cnt + 1);
}
| statement { $$ = new_ast_statelist_node(NULL, $1, 1); }
;The compiler can now handle a function with multiple statements. Running a test, the abstract syntax tree is created as expected: