When we set up the regular expressions for the Lexer, the C code (code within braces) to be executed was only print statements:
"return" {printf("RETURN\n")};
For the Lexer to return tokens to the Parser, we need to modify this C code. For example, when the regular expression “return” is observed, a token representing a return keyword should be returned to the Parser:
"return" { return RETURN; }
In the above code, RETURN is a token that is returned to the Parser. Simply returning a token is sufficient for keywords; however, sometimes we want to return more. Say a number is encountered. We not only want to return a number token, but also return the number that was observed. For this a union called yylval is used.
yylval is a global variable used to pass values between the Lexer and Parser. Since yylval is a union it can pass multiple types of values (note union is definied in Parser):
Once the Parser has accepted a series of tokens as a valid grammar, it will execute C code within the braces after the grammar:
return_st: RETURN ID SEMICOLON {/*C code to be executed when grammar is encountered*/}
What we want the Parser to produce is some form of intermediate representation (IR) that the compiler can analyze to eventually output the program in the XM3 machine’s language. Therefore, most of the C code to be executed when a valid grammar is encountered will produce IR. The IR output by the Parser take the form of abstract syntax trees (AST).
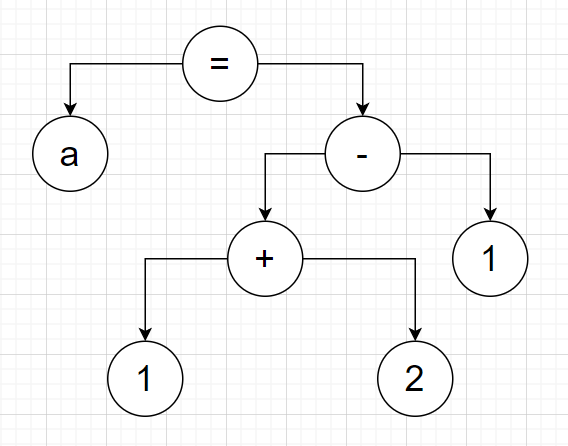
An abstract syntax tree is a tree of nodes that represent a program. For example, take the line of code: “a = 1+2-1;”. An AST for this code could be:
For the compiler, we will use nodes of various types to represent the initial C program as an AST. This AST can be traversed by later sections of the compiler to eventually produce the desired output program.
The first thing required for an AST is a basic node. Note that this node will be type cast later to hold more specific details for the different types of nodes. This basic node will have fields for a node type, left node pointer, and a right node pointer:
Node_Type is an enum of the various possible node types. To start with, the following node types are declared (note that many more types will be required):
Now that the initial node types have been declared in a header file (ast.h), we need functions for the Parser to execute to create these nodes. These functions allocate space for the node, fill the fields of the nodes with the parameters of the function, and return the node. The following functions (in ast.c) are used:
Now that we have declared various node types and have functions to create them, it is possible to generate an AST. However, we still need a function to traverse the AST. To traverse the AST, we can use recursion to travel to the leftmost node of the tree, then work all the way back to the starting node visiting the right node each step of the way. The following function is used to traverse the AST (note that tab_count is a variable used to help print the tree):
int tab_count = -1;
/* Traverse the AST starting from given node, this is done with recursive calls on the child nodes*/
void ast_traverse(AST_Node* node)
{
tab_count++;
// check for empty node
if (!node) {
return;
}
// Nodes with one left child and one right child
if (node->type == BASIC_NODE) {
ast_traverse(node->left);
ast_traverse(node->right);
ast_print_node(node, tab_count);
}
//Function nodes
else if (node->type == FUNC_NODE) {
AST_Node_Func* temp_func = (AST_Node_Func*)node;
ast_traverse(temp_func->statement);
ast_print_node(node, tab_count);
}
// Return nodes
else if (node->type == RETURN_NODE) {
AST_Node_Return* temp_return = (AST_Node_Return*) node;
ast_traverse(temp_return->ret_val);
ast_print_node(node, tab_count);
}
else if (node->type == EXPR_NODE) {
AST_Node_Expr* temp_expr = (AST_Node_Expr*) node;
ast_traverse(temp_expr->left);
ast_traverse(temp_expr->right);
ast_print_node(node, tab_count);
}
// Nodes with no children
else {
ast_print_node(node, tab_count);
}
tab_count--;
}
Finally, for debugging, a print node function was created. This print node function performs a switch case on the node type then prints out the important details of the node. tab_count is also passed to the print node function as it enables the user to see which nodes are children of other nodes. The print function is below:
/* Print a node of any type */
void ast_print_node(AST_Node* node, int tab_cnt)
{
//declare temp node pointers for each node type
AST_Node_Const* temp_const;
AST_Node_ID* temp_ID;
AST_Node_Return* temp_return;
AST_Node_Func* temp_func;
AST_Node_Expr* temp_expr;
for (int i = 0; i < tab_cnt; i++) {
printf("\t");
}
// do a switch on the node type
switch (node->type) {
case BASIC_NODE:
printf("Basic Node\n");
break;
case FUNC_NODE:
temp_func = (AST_Node_Func*) node;
printf("Function Node");
break;
case CONST_NODE:
temp_const = (AST_Node_Const*) node;
printf("Const Node val: %d\n", temp_const->val);
break;
case ID_NODE:
temp_ID = (AST_Node_ID*)node;
printf("ID node: %s\n", temp_ID->varname);
break;
case EXPR_NODE:
temp_expr = (AST_Node_Expr*)node;
printf("Expression node: %c\n", ops[temp_expr->op]);
break;
case RETURN_NODE:
temp_return = (AST_Node_Return*)node;
printf("Return Node type: %d\n", temp_return->ret_type);
break;
default:
printf("Error finding node type, aborting...\n");
break;
}
}
Once the Lexer has converted a C programs characters to a series of tokens, the compiler must check if the order of these tokens lead to valid statements. For this, the Parser is used.
The Parser is passed the tokens from the Lexer then uses a set rules called grammars to check whether valid statements are being passed. For example say the Lexer converts the C code “return a;” to “RETURN ID SEMICOLON”. The Parser would have a grammar to recognize this pattern tokens:
return_st: RETURN ID SEMICOLON {;}
Note, Bison will be used to implement the Parser for the XM3 compiler. Bison is an open source tool used with Flex.
Regular expressions are a sequence of characters that match a pattern of text. For example, “i”,”n”,”t” -> “int”. The Lexer uses regular expressions to create tokens of valid words when analyzing the c program character by character.
An initial list of regular expressions that the Lexer must be able to recognize include identifiers (i.e., variable names), numbers, keywords (i.e., int or while), operators, and some other basic regular expression (i.e., ;).
For keywords and operators the regular expressions are simple as they are just strings. For example, the regular expression to recognize the else keyword is “else”:
"else" {printf("ELSE_TOKEN\n")};
Then, to recognize a number, the first character must be a digit (0, 1, 2, 3, 4, 5, 6, 7, 8, or 9). Then any amount of digits can follow the initial digit. Using regex, the regular expression for a number is:
[0-9]+ {printf("NUMBER_TOKEN\n")};
Finally, to recognize an identifier, the first character must be a letter or an underscore. Then any amount of letters, underscores, and digits can follow the initial character. Using regex, the regular expression for an identifier is:
[a-zA-Z_][a-zA-Z0-9_]* {printf("ID_TOKEN\n")};
Note, that the C code contained in the braces after the regular expressions are executed when the regular expression is encountered. For now, print statements are used, but later these print statements will be replaced by code used to pass tokens to the parser.
See the code below for the initial regular expressions of the Lexer:
The overall goal of our compiler is to take in C code and output the equivalent program in the XM3 machine’s language. The first step in achieving this goal is to make sure our compiler can understand what the input C code is. The first stage in understanding the C code is the Lexer.
The Lexer converts the C code into many tokens. For example, take the C code “int a = 5;”. The Lexer could convert this C statement to the following tokens: INT IDENTIFIER ASSIGN INTEGER SEMICOLON.
These tokens are the compiler recognizing valid words in the C language. Therefore, the purpose of the Lexer is to breakdown the C language into valid words. These words will later be analyzed by the Parser to see if they fit into any valid grammar.
Note, Flex will be used to implement the Lexer for the XM3 compiler. Flex is an open source tool used to generate lexical analyzers.