Looking at the grammar for a function in the Parser, it is observed that the only valid variable type is an integer (INT):
function:
INT ID OP_PAR CL_PAR OP_BRACE statements CL_BRACE {
$$ = new_ast_func_node($6);
}
;
The compiler must be able to handle more variable types such as characters or doubles. The first step to adding new variable types is to create an enum used to distinguish between the different variable types:
Next, the Parser must be updated. First, the tokens must be added to the Parser (must be <intval> tokens as they are also passing the enum values through the yylval union):
%token <intval> CHAR DOUBLE FLOAT INT LONG SHORT VOID /*Variable Types*/
Now, the compiler is able to pass different variable types to the Parser; however, the grammar rules within the Parser still need to be updated. One solution would to be have 7 rules for function where the variable type changes each time. This is inefficient as every time the compiler has a grammar rule with a variable type in it, multiple lines would be required. Therefore, a new %type <intval> called “var_type” will be created:
%type <intval> var_type
The grammar for var_type is set so that it can be any variable type ($1 in this case is the enum value passed through yylval):
The addition of the var_type will not only help with the existing grammar for functions but will also prove useful for other grammar rules with variable types that are to be added in the future (i.e., declarations).
Taking a look at how the function and statement types were previously implemented in the Parser, it is observed that a function can only hold one statement node:
function:
INT ID OP_PAR CL_PAR OP_BRACE statement CL_BRACE {;}
;
statement:
return_st {;}
;
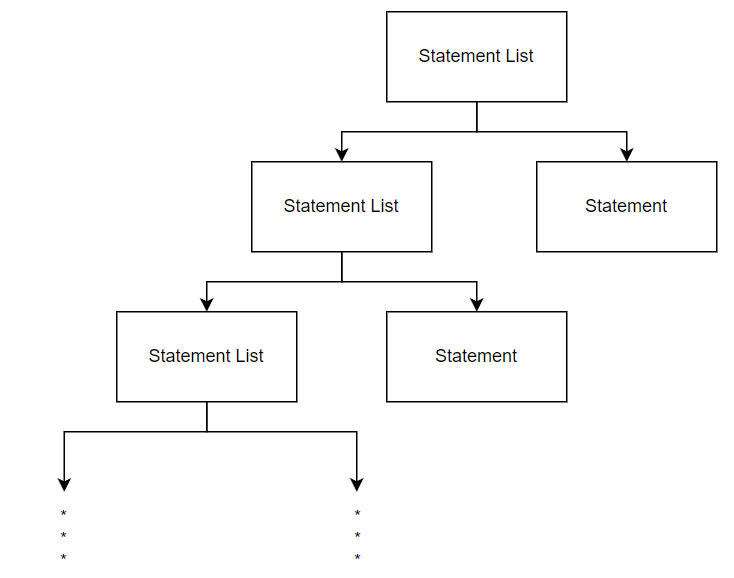
In reality, a function will contain many statements, so the Parser must be modified. To allow a function to contain multiple statements, a statement list node will be used. The statement list node will contain a pointer to a statement node as well as a pointer to another statement list node:
Since a statement list node contains a pointer to another statement list node, any amount of statements can be contained within a single statement list tree. Therefore, if the function node contains a statement list node rather than a statement node, any amount of statement nodes can be contained within a single function.
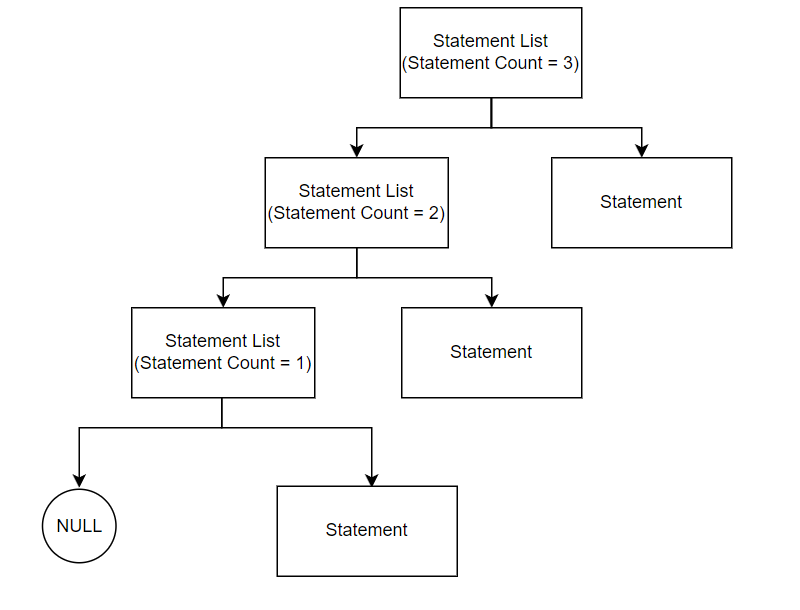
Another field to be implemented in the statement list node is the statement count. The statement count represents how many statement nodes can be found from traversing the tree starting at that particular statement list node. The statement count will be useful later when translating to the XM3 language as the CEX instruction (conditional execution) needs to know the amount of instructions to run/not run. Below shows a statement list tree that uses the statement count:
Now, to implement the statement list node into the compiler. First, a struct for a statement list node is needed for the abstract syntax tree. It will contain fields for the node type, a statement list node pointer, a statement node pointer, and an integer for the statement count:
Then, the Parser needs recursive grammar to enable the creation of statement list nodes. This will require a new %type <node> called statements (refer to the post “Initial Parser” for an explanation of bison types). The two possible grammars for a statements type will be:
A statements type followed by a statement type
A single statement type.
This allows a statements type to represent any amount of subsequent statement types as “statements” is replaced with “statement” or “statements statement” where “statements” can continue to be replaced. See the below code for the implementation of the “statements” type grammar in the Parser (note: function now uses the statements type rather than the statement type):
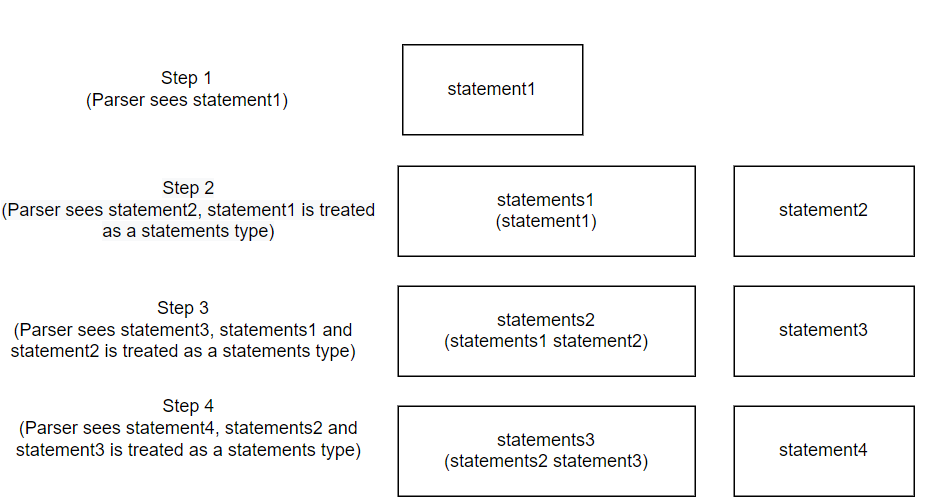
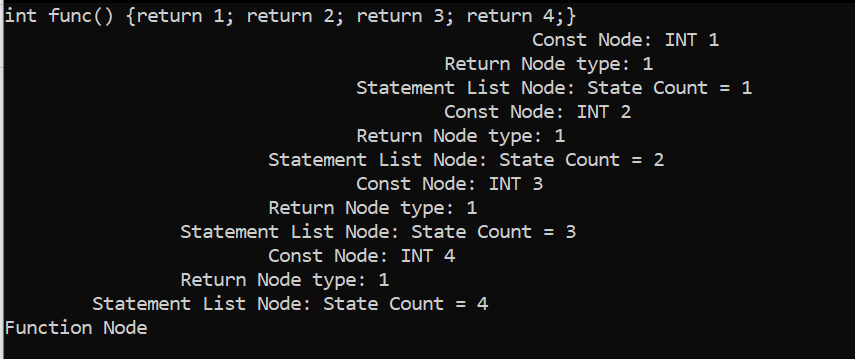
The example below shows a visual representation of the creation of a statements type. Say 4 subsequent statement types are passed to the Parser (note statement1 is passed to the Parser first, and statement4 is passed to the Parser last):
The Parser has been updated to have recursive grammar; however, it still needs C code to create the statement list nodes. For this, the below function is used to create statement list nodes:
Now, it is needed to update the C code in the actual Parser. Again, two cases must be considered as the grammar for the statements type can either be “statements statement” or just “statement”.
First, take the case where the statements type is just “statement”. In this case, only a single statement needs to be handled. Therefore, the pointer to the next statement list node should be NULL. Also, since there are no further statement list nodes, the statement count should be 1. Therefore, the Parser will call the function new_ast_statelist_node with the parameters of statement list node pointer = NULL, statement node pointer = $1 (pointer to statement node returned from statement type), and statement count = 1:
Then, the next case of the statements type being “statements statement”. Take the previous example of there being 4 subsequent statement types. Initially the Parser will only see the first statement. This will be handled as described above for the “statement” case. Then, when the Parser is passed the second statement it will see the grammar as:
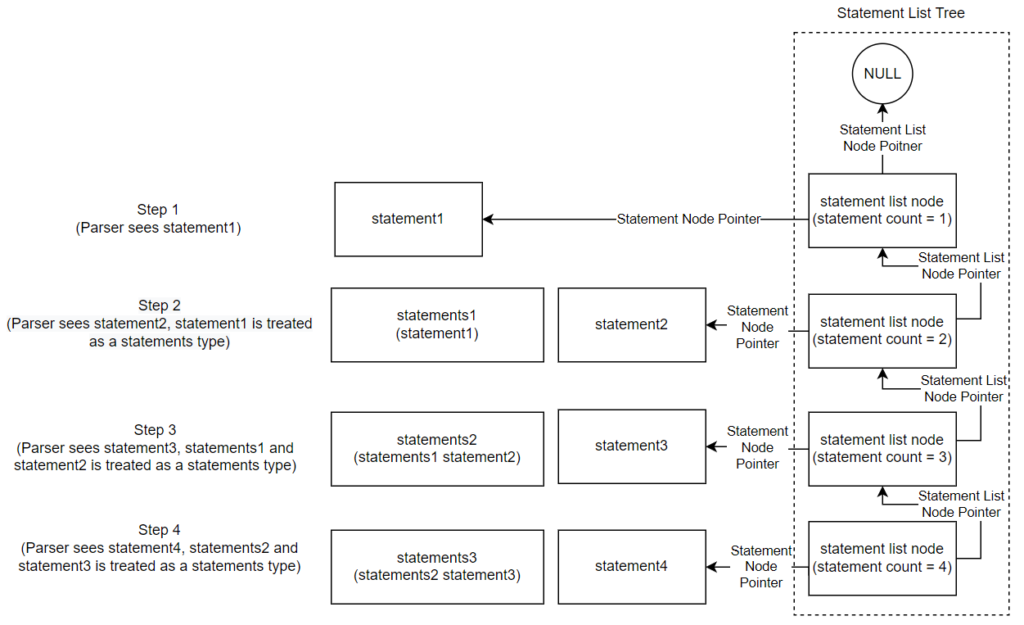
In this case, statements1 is a statement list node where the statement node pointer is to the node for statement1 and statement2 is a statement node. Therefore, the statement list node created for statement2 should have the next statement list node pointer point to statements1, should have the statement node pointer point to statement2, and should have the statement count be 1 greater than that of the statement count in statements1. See below for a visual representation of the abstract syntax tree nodes being created :
Implementing the case of “statements statement” in the Parser requires the statement count field node from statements node to be known. To do this, a temporary node is created to access the field. See below for the implementation of the “statements statement” case:
When the Parser was first set up it only was able to recognize the =, +, -, *, and / operators. More operators are needed to create a C compiler such as logical and bitwise operators. First, the Lexer must be updated to return tokens for these operators. For this, first the enum of operator types was expanded:
Then, the Lexer was updated to return tokens for each of the operators. Note that these operators now also return an integer to be used to set the operator field in an expression node:
Then, the grammar for the expression type must be updated to account for these new operators. Note that now we can use $2 in the create_new_ast_expr_node function rather than an enum as the integer is passed from the Lexer:
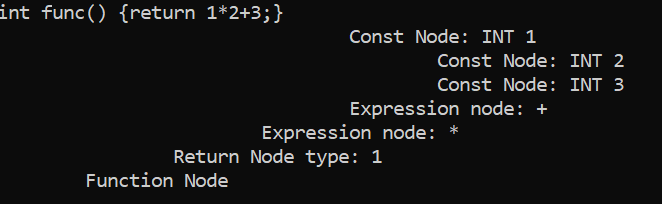
Now are Parser can handle more operators; however, there is no operator precedence. In C, operator precedence is determines what operators should be evaluated before others. For example, take the expression 1*2+3. The multiplication of 1 and 2 should occur first; however, without operator precedence, the compiler evaluates the addition first:
To add operator precedence in bison, the %left and %right tokens can be used. %left is used for left to right precedence (operators on the same precedence level occur left to right) and %right is the inverse of %left. Precedence levels are set up as follows (the lower they are, the earlier they will be evaluated):
%right ASSIGN PLUS_ASSIGN MIN_ASSIGN MULT_ASSIGN DIV_ASSIGN MOD_ASSIGN LSHIFT_ASSIGN RSHIFT_ASSIGN BITAND_ASSIGN BITXOR_ASSIGN BITOR_ASSIGN
%left LOGOR
%left LOGAND
%left BITOR
%left BITXOR
%left BITAND
%left EQ_COMP NOTEQ_COMP
%left GT_COMP LT_COMP GTEQ_COMP LTEQ_COMP
%left R_SHIFT L_SHIFT
%left PLUS MINUS
%left MULT DIVIDE MOD
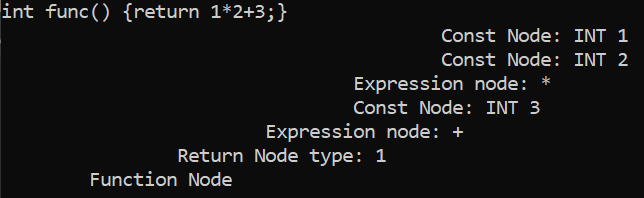
Now running the same expression results in the multiplication occurring first:
There are still more operators to be added but for now a good base has been set and operator precedence has been introduced.
The Parser must be able to take in each of the above tokens and recognize valid grammar rules. The first step is declaring the tokens in the Parser as well as the union used to pass values through yylval. Tokens are declared with %token and the union is declared with %union. If a token is also passing a value through the union it must contain the data type within angle brackets. See the code below for the declarations:
%union {
int intval;
double doubleval;
char charval;
char* str;
struct AST_Node* node;
};
%token RETURN INT
%token SEMI OP_PAR CL_PAR OP_BRACE CL_BRACE EOL EQ
%token PLUS MINUS MULT DIVIDE ASSIGN
%token <intval> ICONST
%token <str> ID
Now that the tokens have been declared, grammar rules need to be set. For a starting point we will be treating a C program as a series of functions. These functions contain statements (i.e., loop statements, if statements, or declarations) which themselves contain expressions (i.e., additions or assignments). Moreover the expressions contain variables and numbers.
The program, functions, statements, and expressions will need to be represented as nonterminal tokens in bison. These nonterminal tokens will be made up of tokens and other nonterminal tokens (which breakdown into tokens) to represent valid grammar rules. For example, the expression nonterminal token would breakdown as follows (note that term is also a nonterminal token):
expression:
term {;}
| variable assign expression {;}
| expression PLUS expression {;}
| expression MINUS expression {;}
| expression MULT expression {;}
| expression DIVIDE expression {;}
;
term:
ICONST {;}
| ID {;}
| OP_PAR expression CL_PAR {;}
;
In the above code the “|” is used to represent alternative options for a nonterminal token. Take the nonterminal token “term”. It can be an integer (ICONST token), a variable (ID token) or an expression within parenthesis (used so that expressions within parenthesis occur before those outside). It is also important to note that the expression nonterminal token contains itself. This means any amount expressions will be represented by a single expression nonterminal token as recursion will occur until only terms and operators are left.
To declare these nonterminal tokens, %type is used. These %types will eventually contain nodes so that the program can be represented as an abstract syntax tree, so <node> will be used. For now, the only statement type the Lexer is passing a token for is a return statement. Therefore, return_st will also be a type (more types will be required in the future):
%type <node> program function statement expression term return_st
Setting the grammar rules for these types results in:
program:
function {;}
;
function:
INT ID OP_PAR CL_PAR OP_BRACE statement CL_BRACE {;}
;
statement:
return_st {;}
;
return_st:
RETURN SEMI {;} /*Return nothing*/
| RETURN expression SEMI {;} /*Return a value*/
;
expression:
term {;}
| variable ASSIGN expression {;}
| expression PLUS expression {;}
| expression MINUS expression {;}
| expression MULT expression {;}
| expression DIVIDE expression {;}
;
term:
ICONST {;}
| ID {;}
| OP_PAR expression CL_PAR {;}
;
In the above code the grammar rules are set but no C code is executed when they are encountered. In bison, $$ represents the output (nonterminal token which in this case is always a node), and $x (where x is the order of the token/nonterminal token in the grammar rule) to represent one of the parts of the grammar. For example, in the below code $$ = nonterminal, $1 = TOKEN1, $2 = nonterminal2, and $3 = TOKEN2:
nonterminal:
TOKEN1 nonterminal2 TOKEN2
;
Adding C code results in the types having functions to creating nodes (see post for creating ast.h and ast.c) except for the program type which calls the function ast_traverse (for now used to print out the abstract syntax tree, but later will be used to create next stage of intermediate representation):
At this point we now have the union, tokens, and types declared. Also, we have the grammar rules and corresponding C code set for the grammar rules. The Parser still requires a lot of expansion (i.e., more operators in expressions, more statements, a function being able to contain multiple statements, and more) but a starting point has been set. The last step to setting up the Parser is defining the default starting symbol of the grammar using %start. For our compiler this is the program type as all the tokens passed to the parser make up a single program:
When we set up the regular expressions for the Lexer, the C code (code within braces) to be executed was only print statements:
"return" {printf("RETURN\n")};
For the Lexer to return tokens to the Parser, we need to modify this C code. For example, when the regular expression “return” is observed, a token representing a return keyword should be returned to the Parser:
"return" { return RETURN; }
In the above code, RETURN is a token that is returned to the Parser. Simply returning a token is sufficient for keywords; however, sometimes we want to return more. Say a number is encountered. We not only want to return a number token, but also return the number that was observed. For this a union called yylval is used.
yylval is a global variable used to pass values between the Lexer and Parser. Since yylval is a union it can pass multiple types of values (note union is definied in Parser):
Once the Parser has accepted a series of tokens as a valid grammar, it will execute C code within the braces after the grammar:
return_st: RETURN ID SEMICOLON {/*C code to be executed when grammar is encountered*/}
What we want the Parser to produce is some form of intermediate representation (IR) that the compiler can analyze to eventually output the program in the XM3 machine’s language. Therefore, most of the C code to be executed when a valid grammar is encountered will produce IR. The IR output by the Parser take the form of abstract syntax trees (AST).
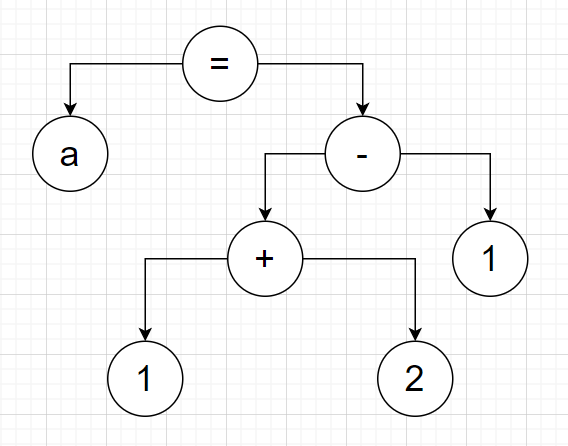
An abstract syntax tree is a tree of nodes that represent a program. For example, take the line of code: “a = 1+2-1;”. An AST for this code could be:
For the compiler, we will use nodes of various types to represent the initial C program as an AST. This AST can be traversed by later sections of the compiler to eventually produce the desired output program.
The first thing required for an AST is a basic node. Note that this node will be type cast later to hold more specific details for the different types of nodes. This basic node will have fields for a node type, left node pointer, and a right node pointer:
Node_Type is an enum of the various possible node types. To start with, the following node types are declared (note that many more types will be required):
Now that the initial node types have been declared in a header file (ast.h), we need functions for the Parser to execute to create these nodes. These functions allocate space for the node, fill the fields of the nodes with the parameters of the function, and return the node. The following functions (in ast.c) are used:
Now that we have declared various node types and have functions to create them, it is possible to generate an AST. However, we still need a function to traverse the AST. To traverse the AST, we can use recursion to travel to the leftmost node of the tree, then work all the way back to the starting node visiting the right node each step of the way. The following function is used to traverse the AST (note that tab_count is a variable used to help print the tree):
int tab_count = -1;
/* Traverse the AST starting from given node, this is done with recursive calls on the child nodes*/
void ast_traverse(AST_Node* node)
{
tab_count++;
// check for empty node
if (!node) {
return;
}
// Nodes with one left child and one right child
if (node->type == BASIC_NODE) {
ast_traverse(node->left);
ast_traverse(node->right);
ast_print_node(node, tab_count);
}
//Function nodes
else if (node->type == FUNC_NODE) {
AST_Node_Func* temp_func = (AST_Node_Func*)node;
ast_traverse(temp_func->statement);
ast_print_node(node, tab_count);
}
// Return nodes
else if (node->type == RETURN_NODE) {
AST_Node_Return* temp_return = (AST_Node_Return*) node;
ast_traverse(temp_return->ret_val);
ast_print_node(node, tab_count);
}
else if (node->type == EXPR_NODE) {
AST_Node_Expr* temp_expr = (AST_Node_Expr*) node;
ast_traverse(temp_expr->left);
ast_traverse(temp_expr->right);
ast_print_node(node, tab_count);
}
// Nodes with no children
else {
ast_print_node(node, tab_count);
}
tab_count--;
}
Finally, for debugging, a print node function was created. This print node function performs a switch case on the node type then prints out the important details of the node. tab_count is also passed to the print node function as it enables the user to see which nodes are children of other nodes. The print function is below:
/* Print a node of any type */
void ast_print_node(AST_Node* node, int tab_cnt)
{
//declare temp node pointers for each node type
AST_Node_Const* temp_const;
AST_Node_ID* temp_ID;
AST_Node_Return* temp_return;
AST_Node_Func* temp_func;
AST_Node_Expr* temp_expr;
for (int i = 0; i < tab_cnt; i++) {
printf("\t");
}
// do a switch on the node type
switch (node->type) {
case BASIC_NODE:
printf("Basic Node\n");
break;
case FUNC_NODE:
temp_func = (AST_Node_Func*) node;
printf("Function Node");
break;
case CONST_NODE:
temp_const = (AST_Node_Const*) node;
printf("Const Node val: %d\n", temp_const->val);
break;
case ID_NODE:
temp_ID = (AST_Node_ID*)node;
printf("ID node: %s\n", temp_ID->varname);
break;
case EXPR_NODE:
temp_expr = (AST_Node_Expr*)node;
printf("Expression node: %c\n", ops[temp_expr->op]);
break;
case RETURN_NODE:
temp_return = (AST_Node_Return*)node;
printf("Return Node type: %d\n", temp_return->ret_type);
break;
default:
printf("Error finding node type, aborting...\n");
break;
}
}
Once the Lexer has converted a C programs characters to a series of tokens, the compiler must check if the order of these tokens lead to valid statements. For this, the Parser is used.
The Parser is passed the tokens from the Lexer then uses a set rules called grammars to check whether valid statements are being passed. For example say the Lexer converts the C code “return a;” to “RETURN ID SEMICOLON”. The Parser would have a grammar to recognize this pattern tokens:
return_st: RETURN ID SEMICOLON {;}
Note, Bison will be used to implement the Parser for the XM3 compiler. Bison is an open source tool used with Flex.
Regular expressions are a sequence of characters that match a pattern of text. For example, “i”,”n”,”t” -> “int”. The Lexer uses regular expressions to create tokens of valid words when analyzing the c program character by character.
An initial list of regular expressions that the Lexer must be able to recognize include identifiers (i.e., variable names), numbers, keywords (i.e., int or while), operators, and some other basic regular expression (i.e., ;).
For keywords and operators the regular expressions are simple as they are just strings. For example, the regular expression to recognize the else keyword is “else”:
"else" {printf("ELSE_TOKEN\n")};
Then, to recognize a number, the first character must be a digit (0, 1, 2, 3, 4, 5, 6, 7, 8, or 9). Then any amount of digits can follow the initial digit. Using regex, the regular expression for a number is:
[0-9]+ {printf("NUMBER_TOKEN\n")};
Finally, to recognize an identifier, the first character must be a letter or an underscore. Then any amount of letters, underscores, and digits can follow the initial character. Using regex, the regular expression for an identifier is:
[a-zA-Z_][a-zA-Z0-9_]* {printf("ID_TOKEN\n")};
Note, that the C code contained in the braces after the regular expressions are executed when the regular expression is encountered. For now, print statements are used, but later these print statements will be replaced by code used to pass tokens to the parser.
See the code below for the initial regular expressions of the Lexer:
The overall goal of our compiler is to take in C code and output the equivalent program in the XM3 machine’s language. The first step in achieving this goal is to make sure our compiler can understand what the input C code is. The first stage in understanding the C code is the Lexer.
The Lexer converts the C code into many tokens. For example, take the C code “int a = 5;”. The Lexer could convert this C statement to the following tokens: INT IDENTIFIER ASSIGN INTEGER SEMICOLON.
These tokens are the compiler recognizing valid words in the C language. Therefore, the purpose of the Lexer is to breakdown the C language into valid words. These words will later be analyzed by the Parser to see if they fit into any valid grammar.
Note, Flex will be used to implement the Lexer for the XM3 compiler. Flex is an open source tool used to generate lexical analyzers.